
voice recognition (speaker recognition)

What is voice recognition (speaker recognition)?
Voice or speaker recognition is the ability of a machine or program to receive and interpret dictation or to understand and perform spoken commands. Voice recognition has gained prominence and use with the rise of artificial intelligence (AI) and intelligent assistants, such as Amazon's Alexa and Apple's Siri.
Voice recognition systems let consumers interact with technology simply by speaking to it, enabling hands-free requests, reminders and other simple tasks.
Voice recognition can identify and distinguish voices using automatic speech recognition (ASR) software programs. Some ASR programs require users first train the program to recognize their voice for a more accurate speech-to-text conversion. Voice recognition systems evaluate a voice's frequency, accent and flow of speech.
Although voice recognition and speech recognition are referred to interchangeably, they aren't the same, and a critical distinction must be made. Voice recognition identifies the speaker, whereas speech recognition evaluates what is said.
This article is part of
A guide to artificial intelligence in the enterprise
How does voice recognition work?
Voice recognition software on computers requires analog audio to be converted into digital signals, known as analog-to-digital (A/D) conversion. For a computer to decipher a signal, it must have a digital database of words or syllables as well as a quick process for comparing this data to signals. The speech patterns are stored on the hard drive and loaded into memory when the program is run. A comparator checks these stored patterns against the output of the A/D converter -- an action called pattern recognition.
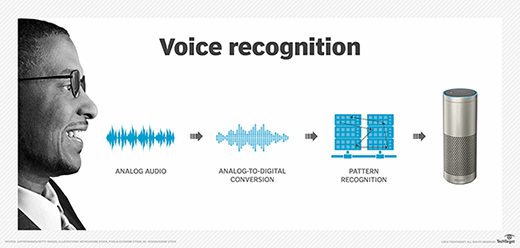
In practice, the size of a voice recognition program's effective vocabulary is directly related to the RAM capacity of the computer in which it's installed. A voice recognition program runs many times faster if the entire vocabulary can be loaded into RAM compared to searching the hard drive for some of the matches. Processing speed is critical, as it affects how fast the computer can search the RAM for matches.
Audio also must be processed for clarity, so some devices may filter out background noise. In some voice recognition systems, certain frequencies in the audio are emphasized so the device can recognize a voice better.
Voice recognition systems analyze speech through one of two models: the hidden Markov model and neural networks. The hidden Markov model breaks down spoken words into their phonemes, while recurrent neural networks use the output from previous steps to influence the input to the current step.
As uses for voice recognition technology grow and more users interact with it, the organizations implementing voice recognition software will have more data and information to feed into neural networks for voice recognition systems. This improves the capabilities and accuracy of voice recognition products.
The popularity of smartphones opened up the opportunity to add voice recognition technology into consumer pockets, while home devices -- such as Google Home and Amazon Echo -- brought voice recognition technology into living rooms and kitchens.
Voice recognition uses
The uses for voice recognition have grown quickly as AI, machine learning and consumer acceptance have matured. Examples of how voice recognition is used include the following:
- Virtual assistants. Siri, Alexa and Google virtual assistants all implement voice recognition software to interact with users. The way consumers use voice recognition technology varies depending on the product. But they can use it to transcribe voice to text, set up reminders, search the internet and respond to simple questions and requests, such as play music or share weather or traffic information.
- Smart devices. Users can control their smart homes – including smart thermostats and smart speakers -- using voice recognition software.
- Automated phone systems. Organizations use voice recognition with their phone systems to direct callers to a corresponding department by saying a specific number.
- Conferencing. Voice recognition is used in live captioning a speaker so others can follow what is said in real time as text.
- Bluetooth. Bluetooth systems in modern cars support voice recognition to help drivers keep their eyes on the road. Drivers can use voice recognition to perform commands such as "call my office."
- Dictation and voice recognition software. These tools can help users dictate and transcribe documents without having to enter text using a physical keyboard or mouse.
- Government. The National Security Agency has used voice recognition systems dating back to 2006 to identify terrorists and spies or to verify the audio of anyone speaking.
Voice recognition advantages and disadvantages
Voice recognition offers numerous benefits:
- Consumers can multitask by speaking directly to their voice assistant or other voice recognition technology.
- Users who have trouble with sight can still interact with their devices.
- Machine learning and sophisticated algorithms help voice recognition technology quickly turn spoken words into written text.
- This technology can capture speech faster than some users can type. This makes tasks like taking notes or setting reminders faster and more convenient.
However, some disadvantages of the technology include the following:
- Background noise can produce false input.
- While accuracy rates are improving, all voice recognition systems and programs make errors.
- There's a problem with words that sound alike but are spelled differently and have different meanings -- for example, hear and here. This issue might be largely overcome using stored contextual information. However, this requires more RAM and faster processors.
For more on artificial intelligence in the enterprise, read the following articles:
What is artificial general intelligence?
History of voice recognition
Voice recognition technology has grown exponentially over the past five decades. Dating back to 1976, computers could only understand slightly more than 1,000 words. That total jumped to roughly 20,000 in the 1980s as IBM continued to develop voice recognition technology.
In 1952, Bell Laboratories invented AUDREY -- the Automatic Digit Recognizer -- which could only understand the numbers zero through nine. In the early to mid-1970s, the U.S. Department of Defense started contributing toward speech recognition system development, funding the Defense Advanced Research Projects Agency Speech Understanding Research. Harpy, developed by Carnegie Mellon, was another voice recognition system at the time and could recognize up to 1,011 words.
The company Dragon in 1990 launched the first speaker recognition product for consumers, Dragon Dictate. This was later replaced by Dragon NaturallySpeaking from Nuance Communications. In 1997, IBM introduced IBM ViaVoice, the first voice recognition product that could recognize continuous speech.
Apple introduced Siri in 2011, and it's still a prominent voice recognition assistant. In 2016, Google launched its Google Assistant for phones. Voice recognition systems can be found in devices including phones, smart speakers, laptops, desktops and tablets as well as in software like Dragon Professional and Philips SpeechLive.
During this past decade, several other technology leaders have developed more sophisticated voice recognition software, such as Amazon Alexa, for example. Released in 2014, Amazon Alexa also acts as a personal assistant that responds to voice commands. Currently, voice recognition software is available for Windows, Mac, Android, iOS and Windows phone devices.





