HTTP (Hypertext Transfer Protocol)
What is HTTP?
HTTP (Hypertext Transfer Protocol) is the set of rules for transferring files -- such as text, images, sound, video and other multimedia files -- over the web. As soon as a user opens their web browser, they are indirectly using HTTP. HTTP is an application protocol that runs on top of the TCP/IP suite of protocols, which forms the foundation of the internet. The latest version of HTTP is HTTP/2, which was published in May 2015. It is an alternative to its predecessor, HTTP 1.1, but does not it make obsolete.
How HTTP works
Through the HTTP protocol, resources are exchanged between client devices and servers over the internet. Client devices send requests to servers for the resources needed to load a web page; the servers send responses back to the client to fulfill the requests. Requests and responses share sub-documents -- such as data on images, text, text layouts, etc. -- which are pieced together by a client web browser to display the full web page file.
In addition to the web page files it can serve, a web server contains an HTTP daemon, a program that waits for HTTP requests and handles them when they arrive. A web browser is an HTTP client that sends requests to servers. When the browser user enters file requests by either "opening" a web file by typing in a URL or clicking on a hypertext link, the browser builds an HTTP request and sends it to the Internet Protocol address (IP address) indicated by the URL. The HTTP daemon in the destination server receives the request and sends back the requested file or files associated with the request.
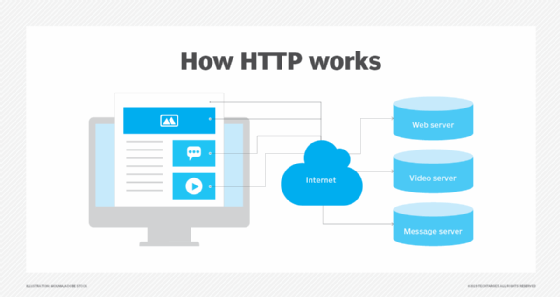
To expand on this example, a user wants to visit TechTarget.com. The user types in the web address and the computer sends a "GET" request to a server that hosts that address. That GET request is sent using HTTP and tells the TechTarget server that the user is looking for the HTML (Hypertext Markup Language) code used to structure and give the login page its look and feel. The text of that login page is included in the HTML response, but other parts of the page -- particularly its images and videos -- are requested by separate HTTP requests and responses. The more requests that are made -- for example, to call a page that has numerous images -- the longer it will take the server to respond to those requests and for the user's system to load the page.
When these request/response pairs are being sent, they use TCP/IP to reduce and transport information in small packets of binary sequences of ones and zeros. These packets are physically sent through electric wires, fiber optic cables and wireless networks.
The requests and responses that servers and clients use to share data with each other consist of ASCII code. Requests state what information the client is seeking from the server; responses contain code that the client browser will translate into a web page.
HTTP vs. HTTPS
HTTPS is the use of Secure Sockets Layer (SSL) or Transport Layer Security (TLS) as a sublayer under regular HTTP application layering. HTTPS encrypts and decrypts user HTTP page requests as well as the pages that are returned by the web server. It also protects against eavesdropping and man-in-the-middle (MitM) attacks. HTTPS was developed by Netscape. Migrating from HTTP to HTTPS is considered beneficial, as it offers an added layer of security and trust.
HTTP requests and responses
Each interaction between the client and server is called a message. HTTP messages are requests or responses. Client devices submit HTTP requests to servers, which reply by sending HTTP responses back to the clients.
HTTP requests. This is when a client device, such as an internet browser, asks the server for the information needed to load the website. The request provides the server with the desired information it needs to tailor its response to the client device. Each HTTP request contains encoded data, with information such as:
- The specific version of HTTP followed. HTTP and HTTP/2 are the two versions.
- A URL. This points to the resource on the web.
- An HTTP method. This indicates the specific action the request expects to receive from the server in its response.
- HTTP request headers. This includes data such as what type of browser is being used and what data the request is seeking from the server. It can also include cookies, which show information previously sent from the server handling the request.
- An HTTP body. This is optional information the server needs from the request, such as user forms -- username/password logins, short responses and file uploads -- that are being submitted to the website.
HTTP responses. The HTTP response message is the data received by a client device from the web server. As its name suggests, the response is the server's reply to an HTTP request. The information contained in an HTTP response is tailored to the context the server received from the request. HTTP responses typically include the following data:
- HTTP status code, which indicates the status of the request to the client device. Responses may indicate success, an informational response, a redirect, or errors on the server or client side.
- HTTP response headers, which send information about the server and requested resources.
- An HTTP body (optional). If a request is successful, this contains the requested data in the form of HTML code, which is translated into a web page by the client browser.
HTTP status codes
In response to HTTP requests, servers often issue response codes, indicating the request is being processed, there was an error in the request or that the request is being redirected. Common response codes include:
- 200 OK. This means that the request, such as GET or POST, worked and is being acted upon.
- 300 Moved Permanently. This response code means that the URL of the requested resource has been changed permanently.
- 401 Unauthorized. The client, or user making the request of the server, has not been authenticated.
- 403 Forbidden. The client's identity is known but has not been given access authorization.
- 404 Not Found. This is the most frequent error code. It means that the URL is not recognized or the resource at the location does not exist.
- 500 Internal Server Error. The server has encountered a situation it doesn't know how to handle.
Proxies in HTTP
Proxies, or proxy servers, are the application-layer servers, computers or other machines that go between the client device and the server. Proxies relay HTTP requests and responses between the client and server. Typically, there are one or more proxies for each client-server interaction.
Proxies may be transparent or non-transparent. Transparent proxies do not modify the client's request but rather send it to the server in its original form. Non-transparent proxies will modify the client's request in some capacity. Non-transparent proxies can be used for additional services, often to increase the server's retrieval speed.
Web developers can use proxies for the following purposes:
- Caching. Cache servers can save web pages or other internet content locally, for faster content retrieval and to reduce the demand for the site's bandwidth.
- Authentication. Controlling access privileges to applications and online information.
- Logging. The storage of historical data, such as the IP addresses of clients that sent requests to the server.
- Web filtering. Controlling access to web pages that can compromise security or include inappropriate content.
- Load balancing. Client requests to the server can be handled by multiple servers, rather than just one.
For more information on how proxies work and more types of proxies, click here.