XML (Extensible Markup Language)
What is XML (Extensible Markup Language)?
XML (Extensible Markup Language) is used to describe data. The XML standard is a flexible way to create information formats and electronically share structured data via the public internet, as well as via corporate networks.
XML is a markup language based on Standard Generalized Markup Language (SGML) used for defining markup languages.
XML's primary function is to create formats for data that is used to encode information for documentation, database records, transactions and many other types of data. XML data may be used for creating different content types that are generated by building dissimilar types of content -- including web, print and mobile content -- that are based on the XML data.
Like Hypertext Markup Language (HTML), which is also based on the SGML standard, XML documents are stored as American Standard Code for Information Interchange (ASCII) files and can be edited using any text editor.
What is XML used for?
XML's primary function is to provide a "simple text-based format for representing structured information," according to the World Wide Web Consortium (W3C), the standards body for the web, including for the following:
- underlying data formats for applications such as those in Microsoft Office;
- technical documentation;
- configuration options for application software;
- books;
- transactions; and
- invoices.
XML enables sharing of structured information among and between the following:
- programs and programs;
- programs and people; and
- locally and across networks.
W3C defines the XML standard and recommends its use for web content. While XML and HTML are both based on the SGML platform, W3C has also defined the XHTML and XHTLM5 document formats that mirror, respectively, the HTML and HTML5 standards for web content.
How does XML work?
XML works by providing a predictable data format. XML is strict on formatting; if the formatting is off, programs that process or display the encoded data will return an error.
For an XML document to be considered well-formed -- that is, conforming to XML syntax and able to be read and understood by an XML parser -- it must be valid XML code. All XML documents consist of elements; an element acts as a container for data. The beginning and end of an element are identified by opening and closing tags, with other elements or plain data within.
XML works by providing properly formatted data that can be reliably processed by programs designed to handle XML inputs. For example, technical documentation may include a <warning> element similar to that shown in the following snippet of XML code:
<warning>
<para>
<emphasis type="bold">May cause serious injury</emphasis>
Exercise extreme caution as this procedure could result in serious injury or death if precautions are not taken.
</para>
</warning>
In this example, this data is interpreted and displayed in different ways, depending on the form factor of the technical documentation. On a webpage, this element could be displayed in the following way:
WARNING: Exercise extreme caution as this procedure could result in serious injury or death if precautions are not taken.
The same XML code is rendered differently on an appliance user interface (UI) or in print. This element could be interpreted to display the text tagged as emphasis differently, such as having it appear in red and with flashing highlights. In printed form, the content might be provided in a different font and format.
XML documents do not define presentation, and there are no default XML tags. Most XML applications use predefined sets of tags that differ, depending on the XML format. Most users rely on predefined XML formats to compose their documents, but users may also define additional XML elements as needed.
XML example
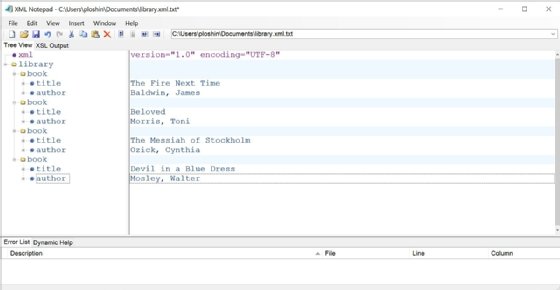
The following is an example of a simple XML file:
<?xml version="1.0" encoding="UTF-8"?>
<library>
<book>
<title>The Fire Next Time</title>
<author>Baldwin, James</author>
</book>
<book>
<title>Beloved</title>
<author>Morris, Toni</author>
</book>
<book>
<title>The Messiah of Stockholm</title>
<author>Ozick, Cynthia</author>
</book>
</library>
The first line in this example, called the XML prolog or XML declaration, specifies the version of XML being used, as well as the character encoding scheme. This declaration, if present, must be the first line of the file.
The prolog specifies that the file contains XML version 1.0 data, encoded using Unicode Transformation Format 8 (UTF-8) encoding, which is the same as ASCII text and specifies the American English character set. Different character encodings can be used for different language character sets, but all XML files must be composed of Unicode characters. Any Unicode character can be represented in an XML file using a numeric character reference with a string in this format:
&#xXXXX;
In this format, the letters "XXXX" are substituted with a valid hexadecimal Unicode numeric code.
XML elements
The logical structure of an XML file requires that all data in the file be encapsulated within an XML element called the root element or document element. This element identifies the type of data contained in the file; in the example above, the root element is <library>.
The root element contains other elements that define the different parts of the XML document; in the example above, the root element contains <book> elements, which, in turn, consist of the two elements <title> and <author>.
All XML elements must be properly terminated for an XML file to be considered well-formed. This means that a tag must be properly terminated with an opening and closing tag, like this paragraph element that would be a part of a document:
<para>This is an example of an XML tag for a paragraph.</para>
A tag can also be empty, in which case it is terminated with a forward slash. In this example, an empty self-terminating paragraph tag is used to insert an extra space in a document:
<para />
XML enables users to define their own additional elements if needed. In the preceding example, an XML author might define new elements for publisher, date of publication, International Standard Book Number and any other relevant data. The elements can also be defined to enforce rules regarding the contents of the elements.
XML entities
XML elements can also contain predefined entities, which are used for special reserved XML characters. Custom entities can be defined to insert a predefined string of characters for inclusion in an XML file.
The five standard predefined XML entities are the following:
- < -- The less than symbol (<), also known as the open angle bracket, is normally used in XML to indicate the start of an XML tag. This entity is used when the open angle bracket is part of the content of the XML file.
- > -- The greater than symbol (>), also known as the close angle bracket, is normally used in XML to indicate the end of an XML tag. This entity is used when the close angle bracket is part of the content of the XML file.
- & -- The ASCII ampersand symbol (&) is reserved in XML for indicating the start of an XML entity. This entity is used when an ampersand occurs within an XML element.
- " -- The ASCII double quote character (") is used in XML element tags to identify optional attribute values of the element. For example, an <emphasis> tag might include options for emphasizing some text, such as bold, italic or underline. This entity is used when a double quote character appears in the contents of an XML element.
- ' -- The ASCII single quote character ('), also known as an apostrophe, is used in XML element tags to identify option attributes of the element. For example, an <emphasis> tag might include options for emphasizing some text, such as bold, italic or underline. This entity is used when a single quote or apostrophe appears in the contents of an XML element.
XML entities take the form of &name; where the entity name begins with the ampersand symbol and ends with a semicolon. Custom entities can be single characters or complex XML elements. For example, boilerplate language for technical documentation or legal contracts can be reduced to a single entity. However, when using entities, the XML author must ensure that inserting the entity into an XML file will produce well-formed XML data.
Is XML a programming language?
XML is not a programming language. However, as a markup language, it is used to annotate data using tags, which interpret that data. Programming languages consist of instructions to implement algorithms, while markup languages are used to format data for processing by programs running algorithms that interpret marked-up data.
Markup language tags are considered a type of computer code because they define different elements of the markup language and because there are strict syntax rules for how to compose those elements.
What is an XML file?
An XML file is a plaintext file with the .xml file extension. XML files contain Unicode text, and they can be opened with any application capable of reading text files.
XML files can be edited either with a simple text editor or specialized XML editors. An XML editor may include tools for validating the XML code, including the ability to do the following:
- parse XML code and display well-formed XML;
- flag orphaned text, which is text not enclosed within a tag; and
- identify improperly formed tags.
Different types of content can be incorporated into an XML file. For example, rich media content can be incorporated into XML through tags that identify the files in which the rich media content resides.
How to open and read XML files
Any text editor can be used to open and edit an XML file. While text editors may be sufficient for casual XML file editing, specialized XML editing software is preferred for any extensive writing or editing of XML files. XML editing programs ease editing XML files with the following features:
- syntax highlighting for tracking complex XML tags;
- XML parser for checking validity of XML code and displaying parsed data;
- expanding or collapsing XML tags and nodes;
- enhanced interface for editing multiple files at once;
- graphical UI enabling visual display of relationships between XML elements and simplified display of complex XML elements, like tables; and
- productivity tools, like macros, custom elements, and search and replace functions.
Some leading XML editing programs are the following:
- Oxygen XML Editor
- XML Notepad
- Adobe FrameMaker
- MadCap Flare
- Quark Author
- Liquid XML Studio
XML files are structured much like any other type of programming code, with headers defining the contents of the file and indentation for nested elements.
What are the differences between XML and HTML?
While XML and HTML share the same underlying SGML foundations, they are different and are used in different ways.
The biggest difference between XML and HTML is that XML is used to store data as structured information, while HTML is used to represent content. Because XML stores data and because it enforces strict validation, XML content can be reliably processed by programs. This is why XML is often used to create files that are used to generate HTML content.
Strict validation of XML code means that, if there are errors in the code, it will fail when it is processed for output. Users can then correct the XML code so it can be successfully processed. This is crucial for HTML content that is based on XML but also makes XML an important format for software configuration files that must be well-formed in order to be successfully processed by software.

What is the benefit of using XML for documentation?
XML is widely used for technical documentation because it can specify structural information. This document structure can then be parsed by other programs for output.
For example, in HTML, the user can create different types of lists, including numbered lists, but there is no way to explicitly tag content as being part of a step-by-step procedure. In XML, a procedure tag can be defined to represent a list of items as being the steps of a procedure, including identifying different elements for required steps, optional steps and alternate steps.
Likewise, in HTML, a string can be tagged as one of several different heading levels to indicate a headline or title, but in XML, a string can be explicitly tagged as a title, subtitle, headline or subheadline. This enables the user to differentiate programs to process the XML content for different types of output.
For example, if the content is to be output in printed book form, the book or chapter title can be incorporated into a header or footer. If the content is to be output as HTML content, the book or chapter title could be incorporated into a webpage as needed.
As the foundational format for storing data of all types, XML drives much more than technical documentation. Learn about other formats that compete with XML for data representation, especially JavaScript Object Notation (JSON) and YAML Ain't Markup Language (YAML) data formats.