trunk-based development

What is trunking for development?
In software development, a trunk is the base code into which all subsequent code is merged. Copies made from the source code are known as branches, extending outward from the trunk.
Trunk-based development is a branching model whereby software designers regularly make small code changes to a single shared branch in the version control system. The shared branch, or trunk, is also called the baseline or mainline branch.
Software trunking should not be confused with trunking in networking. The latter term describes the infrastructure of a physical line or link that can carry many signals simultaneously for network access between two points.
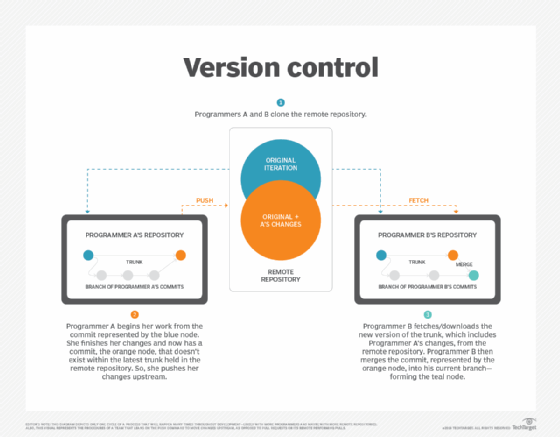
Trunk-based development approaches and styles
Trunking helps a development team avoid lengthy code integration tasks and improve its efficiency. All changes are pushed directly to the trunk, even if not in final form. Errors are addressed quickly and remediated before they go live.
Project teams run automated unit tests before each commit, or change, to identify and resolve code conflicts. Pair programming teams, or a similar review process, ensure each line of work is scrutinized before moving to the trunk.
The trunking approach diverges from features-based branching methods in the following ways:
- The trunk is constantly in use. The trunk is the sole repository for code development. Direct-to-trunk commits encompass code designed to create or publish artifacts.
- Long-lived feature branches play little to no role. A DevOps team may deploy short-lived feature branches to address issues caught during code review. A short-lived feature branch gets immediately merged in the trunk and then deleted.
Trunk-based development vs. Gitflow
To understand the role of trunk-based development, it is useful to compare it to Agile software development methods, particularly open source Git. Both styles strive for continuous integration (CI) and continuous delivery, but they differ in how they work and the way they are used. A big difference is in the version control systems.
Trunking
With trunking, features are made available sooner without wholesale rewrites, while preserving software build quality. The trunk code should be maintained in a production-ready state to support the following elements:
- dynamic code changes on the fly as a project evolves;
- rollbacks to an earlier version to remediate errors quickly;
- more predictable control when implementing features; and
- less complex merge events.
Git development
Git development is a features-based approach that the Gitflow workflow tool manages. Long-lived feature branches are widely deployed to maintain code changes. A developer creates a new feature branch off the trunk, works on it and then creates pull requests to get feedback from team members.
In Gitflow, each branch is assigned a role. There are rules governing how the branches interact. Gitflow offers more control over which features get merged than trunking. Gitflow is often associated with prepackaged software builds that users download.
Git integration is also weightier. Each branch is developed independently and isolated to ensure the original code remains stable. All changes are merged at the same time, increasing the risk of code conflicts.
The Gitflow repository uses two branches to track a project's history: a mainline branch and a develop branch:
- The mainline branch holds all production code and release history.
- The develop branch, or integration branch, contains new feature code and aggregates features awaiting deployment by the mainline branch.
The result of branching is a major release branch that incorporates all minor revisions in the trunk. The existing release branch is deleted and a new one is carved out of the code base. In trunking, one or two release engineers manage the cadence of a final release branch. In Git, Gitflow manages this process, merging only release branches and bug fixes in the trunk.
Benefits of trunk-based development
Reduced complexity is a major emphasis of trunk-based software design. With the trunk as a shared repository, software gets amended and shipped to production at an accelerated pace. Working in trunk positions enables a software team to certify that all major releases will happen without a problem. Teams achieve a higher level of performance because the product release cycle is predictable.
Although not suitable for every environment, using the trunk method helps development teams do the following:
- Speed up reviews. Developers build a strong feedback loop. Trunking does not rely on pull requests.
- Avoid code drift. Developers iterate rapidly while maintaining quality.
- Drive CI. Updates are visible to other developers, generating more timely reviews.
- Foster collaboration. Developers can see all changes and can cross-pollinate each other's contributions.
- Improve refactoring. Decomposing an application story into a series of small components takes less time.
- Promote faster integration. All developers take responsibility for quality assurance.
- Reduce merger pain. Because trunking is lightweight, it avoids merger collisions, helping to lower development costs. Periodic commits avoid complex code merges that could potentially break the software build.
How to implement trunk-based development
Trunk-based development does have some drawbacks. The fast-paced environment is most often associated with larger organizations with senior DevOps engineers who work on tight timelines. These software designers need to be able to:
- build code locally to assess the impact on applications and any dependencies;
- deploy short-lived feature flags or toggles to test functionality while keeping it hidden from end users;
- design automated unit tests and test-driven development techniques as part of application programming interface documentation;
- ensure code works as intended before committing to trunk;
- request code review from other team members; and
- seek consensus on when changes are ready to be merged.
By contrast, developing in Git or another Agile-based framework is generally considered a more suitable implementation for organizations that:
- follow a long or indeterminate software development lifecycle;
- have many junior engineers;
- integrate feature requests from many developers;
- manage a monolithic code base;
- need to restrictive source control; and
- specialize in open source projects.
Trunk-based development: Best practices
The principle behind trunk-based development is to assimilate every change as soon as possible in version control. This keeps the continuous integration process moving along. But developers used to Agile-type branching must adopt a different mindset.
Industry best practices for trunk-based software include the following six steps:
- Develop. Set only one branch -- the trunk -- as the target.
- Code. Subdivide it and deploy small batches.
- Commit. Ship updates promptly and consistently, usually several times per day.
- Plan. Use feature branches sparingly and merge them into the mainline daily.
- Test. Feedback, testing and ongoing reviews will help find and correct errors.
- Manage. Try writing utilities for tooling in-house.
Learn more about how trunk-based development compares to featured-based methodologies.