biometric authentication
What is biometric authentication?
Biometric authentication is a security process that relies on the unique biological characteristics of individuals to verify they are who they say they are. Biometric authentication systems compare physical or behavioral traits to stored, confirmed, authentic data in a database. If both samples of the biometric data match, authentication is confirmed. Typically, biometric authentication is used to manage access to physical and digital resources, such as buildings, rooms and computing devices.
Biometric identification uses biometrics, such as fingerprints, facial recognition or retina scans, to identify a person, whereas biometric authentication is the use of biometrics to verify people are who they claim to be.
Types of biometric authentication methods
The following examples of biometric technology -- built using computer vision algorithms -- can be used to digitally identify people or grant them permission to access a system:
- Chemical biometric devices
- DNA (deoxyribonucleic acid) matching uses genetic material to identify a person.
- Visual biometric devices
- Retina scans identify subjects by analyzing the unique pattern of blood vessels at the back of their eyes.
- Iris recognition uses a picture of the iris to identify people in an iris scan.
- Fingerprint scanners identify people based on their fingerprints.
- Hand geometry recognition verifies identity or authorizes transactions using a mathematical representation of the unique characteristics of people's hands. This is done by measuring the distances between various parts of the hand, including finger length, finger breadth and the shape of the valleys between the knuckles.
- Facial recognition relies on the unique characteristics and patterns of people's faces to confirm their identity. The system identifies 80 nodal points on a human face, which make up numeric codes called faceprints.
- Ear authentication verifies identity based on users' unique ear shape.
- Signature recognition uses pattern recognition to identify individuals based on their handwritten signature.
- Vein or vascular scanners
- Finger vein recognition identifies individuals based on the vein patterns in their finger.
- behavioral biometrics
- Gait analysis examines the way people walk.
- Typing recognition establishes people's identity based on their unique typing characteristics, including how fast they type.
- Auditory biometric devices
- Voice ID identifies individuals with voice recognition and relies on characteristics created by the shape of the mouth and throat.
What are the components of biometric authentication devices?
A biometric device includes three components: a reader or scanning device, technology used to convert and compare collected biometric data, and a database for storage.
A sensor is a device that measures and captures biometric data. For example, it could be a fingerprint reader, voice analyzer or retina scanner. These devices collect data to compare to the stored information for a match. The software processes the biometric data and compares it to match points in the stored data. Most biometric data is stored in a database that is tied to a central server on which all data is housed. However, another method of storing biometric data is cryptographically hashing it to allow the authentication process to be completed without direct access to the data.
What is multimodal biometric authentication?
Multimodal biometric authentication adds layers to an authentication process by requiring multiple identifiers, which are read simultaneously during the process. This can be considered a form of multifactor authentication (MFA), though clearly much different than the better-known form where sensitive information is entered into a mobile and/or desktop device.
Increased security without the need for key cards, access cards, passwords or personal identifaction numbers is among the advantages for organizations that choose to adopt this approach. Additionally, malicious actors who attempt to hack or fake their way through an authentication system have a harder time faking two or more unique characteristics of an individual than if they were to try faking only one.
However, this approach also comes with a few disadvantages, as high costs can be incurred when assembling and implementing the tools needed, such as scanners, computing power and storage space for biometric data. Also, it can intensify public perception that an organization is collecting and storing personal information unnecessarily, which can then be used to surveil people with or without their consent.
What are the use cases of biometric authentication?
Examples of areas where biometric authentication is used include the following.
Law enforcement
Law enforcement and state and federal agencies use different kinds of biometric data for identification purposes. These include fingerprints, facial features, iris patterns, voice samples and DNA.
For example, Automated Fingerprint Identification System (AFIS) is a database that is used to identify fingerprints. It was first used in the early 1970s as a way for police departments to automate their otherwise manual fingerprint identification process, making it quicker and more effective. In the past, a trained human examiner had to compare a fingerprint image to the prints on file. If there was a match, the examiner would double-check the two prints to verify the match. Today, AFIS can match a fingerprint against a database of millions of prints in a matter of minutes.
Travel
An electronic passport (e-passport) is the same size as a conventional passport and contains a microchip that stores the same biometric information as a conventional passport, including a digital photograph of the holder. A chip stores a digital image of the passport holder's photo, which is linked to the owner's name and other personally identifiable information. The e-passport is issued electronically by a country's issuing authority, which checks the identity of the applicant through fingerprints or other biometric information and confirms the data in the chip with the information provided by the applicant before issuing the passport.
Healthcare
Hospitals use biometrics to more accurately track patients and prevent mix-ups, while clinics and doctors' offices implement biometric authentication to keep their patients' information secure. Using biometric data, hospitals can create digital identities of patients that help them to store and access those patients' medical histories. This information can be used to ensure the right patient gets the right care, whether that means faster identification in emergency situations or preventing medical errors.
Identity and access management systems
An identity and access management (IAM) system is a combination of policies and technology tools that collectively form a centralized means of controlling user access to important information a business has stored. IAM systems use methods like single sign-on, two-factor authentication and MFA, as well as sophisticated tools, like biometrics, analysis of behavioral characteristics, artificial intelligence and machine learning, as part of its overall strategy to make authentication more rigorous and secure.
Payments
The use of biometric authentication in payments and credit card processing is nascent and slowly expanding. The general idea is to add more security to payments without added complexities or frustrations. Examples of these biometric payments often have consumers using cards to pay for goods, but those transactions are only authorized after they scan their fingerprint, eye or face. There is more than one way to scan as well since cards can have built-in sensors to scan fingerprints, while a register or kiosk may have scanners readily available.
What are the advantages and disadvantages of biometric authentication?
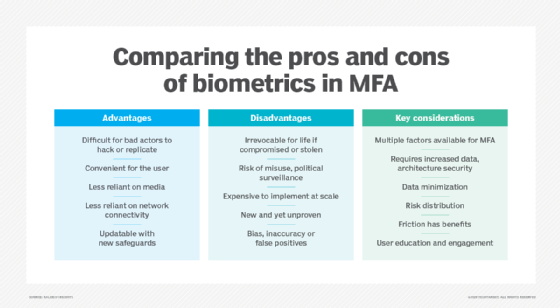
Biometric authentication has its advantages and disadvantages.
The advantages of biometric authentication are its convenience and security. Since biometric authentication uses unique characteristics for verification, they are difficult to replicate. Traditional methods, such as usernames, passwords or ID cards, are not as secure because they can be stolen or guessed easily. In the United States alone, business use of biometric authentication has drastically increased in recent years as more business leaders are becoming more confident in its capabilities.
While biometrics offers many advantages for particular industries, there are controversies surrounding its usage. Organizations may overlook the security of these data-driven security schemes. If bad actors capture biometric data when it is being transmitted to a central database, they can fraudulently replicate that data to perform another transaction. For example, by capturing an individual's fingerprint and using it to access a fingerprint-secured device, hackers or other bad actors could access sensitive data, such as private messages or financial information.
Another potential issue with biometric authentication is that, once a security system has been implemented, an organization may be tempted to use the system for functions beyond its original intention, which is known as function creep. For example, a company may find the technology useful for employee monitoring and management, but once a biometric system has been installed, the organization may find that it has the ability to track exactly where an employee has been.
Learn more about biometric payments, which are real-world applications of biometric authentication technology for financial transactions, and more about the pros and cons of biometric authentication. See why biometric interfaces unlock new capabilities and risks with IoT sensors and how a major facial recognition supplier built a system to identify masked faces.






