
Sergey Nivens - Fotolia
Top 25 big data glossary terms you should know
Big data knowledge and awareness can help businesses and individuals get ahead. Understanding the most important terms in big data is an excellent place to start that journey.

The significance of big data doesn't lie in the volume of data a business has accumulated. Its true value lays in how that data is used. Forward-looking organizations understand they need to capitalize on the potential of big data through its practical and thoughtful use to inform, steer and refine business decision-making.
Businesses and individuals in all industries have woken up to the potential benefits of big data and analytics. If you're interested in the field of big data -- whether you're a student contemplating it as a career path, or a business or technology professional looking to brush up on your knowledge -- getting up to speed on the most important big data terminology is a must.
To help get you started, we have collected key big data terms in this convenient glossary.
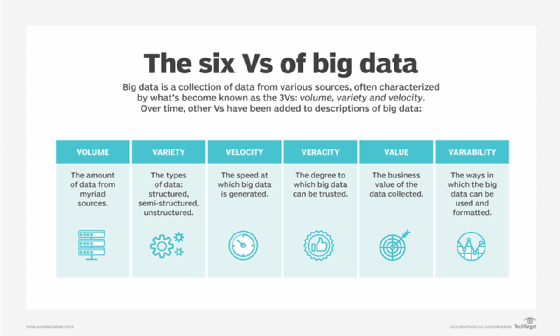
The top 25 big data terms you should know
- Algorithm: A procedure or formula for solving a problem based on conducting a sequence of specified actions. In the context of big data, algorithm refers to a mathematical formula embedded in software to perform an analysis on a set of data.
- Artificial intelligence: The simulation of human intelligence processes by machines, especially computer systems. These machines can perceive the environment and take corresponding required actions and even learn from those actions.
- Cloud computing: A general term for anything that involves delivering hosted services over the internet. For big data practitioners, cloud computing is important because their roles involve accessing and interfacing with software and/or data hosted and running on remote servers.
- Data lake: A storage repository that holds a vast amount of raw data in its native format until it's required. Every data element within a data lake is assigned a unique identifier and set of extended metadata tags. When a business question arises, users can access the data lake to retrieve any relevant, supporting data.
- Data science: The field of applying advanced analytics techniques and scientific principles to extract valuable information from data. Data science typically involves the use of statistics, data visualization and mining, computer programming, machine learning and database engineering to solve complex problems.
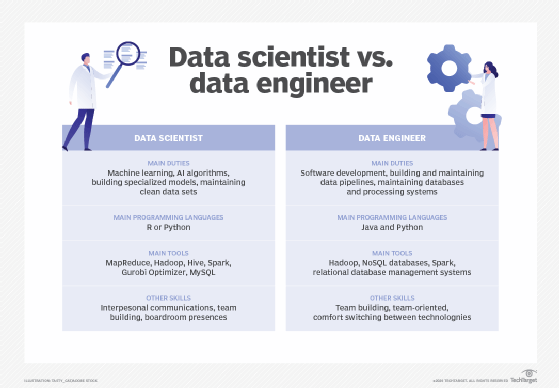
- Database management system (DBMS): System software that serves as an interface between databases and end users or application programs, ensuring that data is consistently organized and remains easily accessible. DBMSes make it possible for end users to create, protect, read, update and delete data in a database.
- Data set: A collection of related, discrete items of data that may be accessed individually or collectively, or managed as a single, holistic entity. Data sets are generally organized into some formal structure, often in a tabular format.
- Hadoop: An open-source distributed processing framework that manages data processing and storage for big data applications. It provides a reliable means for managing pools of big data and supporting related analytics applications.
- Hadoop distributed file system (HDFS): The primary data storage system used by Hadoop HDFS employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters.
- Machine learning: A type of artificial intelligence that improves software applications' ability to predict accurate outcomes without being explicitly programmed to do so. Common use cases for machine learning include recommendation engines, fraud and malware threat detection, business process automation and predictive maintenance.
- MapReduce: Specific tools that support distributed computing on large data sets. These form core components of the Apache Hadoopsoftware framework.
- Natural language processing (NLP): A computer program's ability to understand both written and spoken human language. A component of artificial intelligence, NLP has existed for over five decades and has roots in the field of linguistics.
- NoSQL: An approach to database design that can accommodate a wide variety of data models, including key-value, document, columnar and graph formats. NoSQL, which stands for "not only SQL," is an alternative to traditional relational databases in which data is placed in tables and data schemais carefully designed before the database is built. NoSQL databases are especially useful for working with large sets of distributed data.
- Object-based image analysis: The analysis of digital images using data from individual pixels. It combines spectral, textural and contextual information to identify thematic classes in an image.
- Programming language: Used by developers and data scientists to perform big data manipulation and analysis. R, Python, and Scala are the three major languages for data science and data mining.
- Pattern recognition: The ability to detect arrangements of characteristics or data that provide information about a given system or data set. Patterns could manifest as recurring sequences of data that can be used to predict trends, specific configurations of features in images that identify objects, frequent combinations of words and phrases or clusters of activities on a network that could indicate a cyber attack.
- Python: An interpreted, object-oriented programming language that's gained popularity for big data professionals due to its readability and clarity of syntax. Python is relatively easy to learn and highly portable, as its statements can be interpreted in several operating systems.
- Qualifications and learning resources for big data careers: Students exploring a career in big data, and even established professionals seeking to augment their existing experience, have a host of options and resources at their disposal to advance their ambitions and grow their big data skills. These include university degrees at both undergraduate and graduate levels as well as online certifications and learning modules.
- R programming language: An open source scripting programming language used for predictive analytics and data visualization. R includes functions that support both linear and nonlinear modeling, classical statistics, classifications and clustering.
- Relational databases: A collection of information that organizes data points with defined relationships for easy access. Data structures (including data tables, indexes and views) remain separate from the physical storage. This enables administrators to edit the physical data storage without affecting the logical data structure.
- Scala: A software programming language that blends object-oriented methods with functional programming capabilities. This allows it to support a more concise programming style which reduces the amount of code that developers need to write. Another benefit is that Scala features, which operate well in smaller programs, also scale up effectively when introduced into more complex environments.
- Soft skills: Today's most successful big data professionals are those who can harmonize their academic qualifications, innate intellectual abilities and real-world experience with a diverse range of other softer skills. These soft skills include tenacity, problem-solving abilities, curiosity, effective communication, presentation and interpersonal skills, and well-rounded business understanding and acumen.
- Statistical computing: The collection and interpretation of data aimed at uncovering patterns and trends. It may be used in scenarios such as gathering research interpretations, statistical modeling or designing surveys and studies, and advanced business intelligence. R is a programming language that's highly compatible with statistical computing.
- Structured data: Structured data is data that has been organized into a formatted repository, typically a database, so that its elements can be made addressable for more effective processing and analysis.
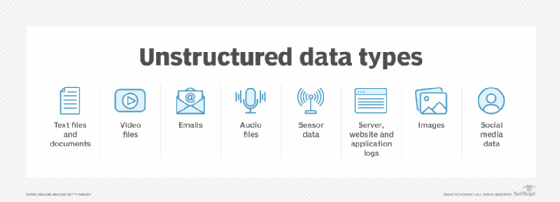
- Unstructured data: Everything that can't be organized in the manner of structured data. Unstructured data includes emails and social media posts, blogs, and messages, transcripts of audio recordings of people's speech, images and video files, and machine data, such as log files from websites, servers, networks and applications.
Learn more about big data, its terminology and what it means to succeed in this field by reading our guide to big data best practices, tools and trends.







