IT incident management

What is IT incident management?
IT incident management is an area of IT service management (ITSM) wherein IT teams return a service to normal as quickly as possible after a disruption with as little negative impact on the business as possible.
An incident is an unexpected event that disrupts the normal operation of an IT service. A problem is an underlying issue that could lead to an incident. Problem management is the measures taken to prevent the occurrence of an incident.
IT incident management helps keep an organization prepared for unexpected hardware, software and security failings, and reduces the duration and severity of disruptions from these events. It can follow an established ITSM framework, such as IT infrastructure library (ITIL), COBIT, or be based on a combination of guidelines and best practices established over time.
IT incident management process
In practice, IT incident management often relies upon temporary workarounds to ensure services are up and running while IT staff investigates the incident, identifies its root cause, and develops and rolls out a permanent fix. Workflows and processes in IT incident management differ depending on the way each IT organization works and the issue they are addressing.
Most IT incident management workflows begin with users and IT staff pre-emptively addressing potential incidents, such as a network slowdown. IT staff contain the incident to prevent potential issues in other areas of the IT deployment. Then, they find a temporary workaround or implement a system fix and recovery and release it back into the production environment. IT staff then review and log the incident for future reference.
Documentation enables IT staff to find previously unseen and recurring incident trends and address them. If a temporary workaround is in place, once the disruption to end users is mitigated, IT staff can develop a long-term fix for the issue.
A focus on IT incident management processes and established best practices will minimize the duration of an incident, shorten recovery time, and help prevent future issues.
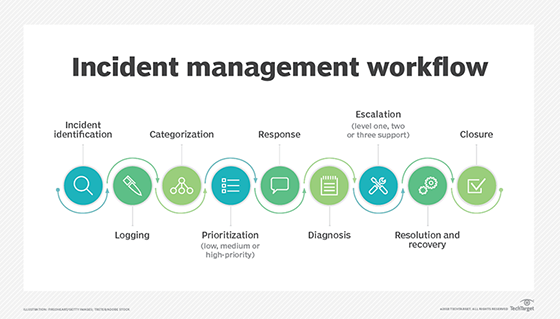
A common framework to understand IT incident management is through analyzing the ITIL process. ITIL, trademarked by Axelos, is a widely used ITSM framework. ITIL incident management uses a workflow for efficient resolution: incident identification, logging, categorization, prioritization, response, diagnosis, escalation, resolution and recovery, and closure.
Types of incidents
Incidents are generally categorized by low, medium and high priorities.
- Low-priority incidents do not interrupt end users, who typically can complete work despite the issue.
- Medium-priority incidents are issues that affect end users, but the disruption is either slight or brief.
- High-priority incidents are issues that will affect large amounts of end users and prevent a system from functioning properly.
Incidents are classed as hardware, software or security, although a performance issue can often result from any combination of these areas. Software incidents typically include service availability problems or application bugs. Hardware incidents typically include downed or limited resources, network issues or other system outages. Security incidents encompass attempted and active threats intended to compromise or breach data. Unauthorized access to personally identifiable records is a security issue, for example.
Roles in incident management
IT incident management is normally separated into three levels of support, generally grouped together in the help or service desk. Most organizations use a support system, such as a ticketing system, for categorization and prioritization of incidents. IT staff respond to each incident according to its prioritization level.
Level-one support typically provides basic-level support or assistance, such as password resets or computer troubleshooting. Level-one support involves incident identification, logging, prioritization and categorization, deciding to escalate to level-two support and incident resolution when appropriate. Level-one support involves technical staff that is trained to solve common incidents and fulfill basic service requests.
Level-two support goes through a similar process for more complex issues that need more training, skill or security access to complete. Level-two support includes IT staff with specific knowledge of the system in question.
Major incidents are given to level-three support. This category includes incidents that disrupt a business's operation, marked as a high priority and require an immediate response. Such an example would be an issue with a network that requires an expert or a skilled team to solve.
Level-three support team members are generally specialists in the subject matter of the incident. For example, a level-three support team could include the chief architect and engineers who work on the product or service's daily operation and maintenance.
An incident manager enforces the proper response and management processes across IT support and service delivery teams. This person can be involved in the organization's choice of ITSM framework. They should work to improve how the company prevents and handles incidents over time, through risk mitigation and ongoing process improvements. The incident manager is likely to act as a communication bridge between end users and technical specialists during disruptions, such as an email outage. The person produces, along with the service desk staff, incident reports for critical business and IT services, and they might lead a post-mortem on major incidents. They also maintain a knowledgebase of problems and incidents.
In DevOps organizations, software developers are considered responsible for production-ready code, under a mantra of, "You build it, you own it." In the event of a software incident, the developer should participate in or lead incident management.
Incident management tools
Help desk and incident management teams rely on a mix of tools to resolve incidents, such as monitoring tools to gather operations data, root cause analysis systems and incident management and automation platforms.
Monitoring tools enable IT staff to pull operations data from across multiple systems, such as on-premises or cloud-based hardware and software. Root cause analysis tools help sort through operational data, such as logs, which were collected by systems management, application performance monitoring and infrastructure monitoring tools. Root cause analysis tools help IT staff understand how a system operates and where any incidents reside.
Incident response tools correlate that monitoring data and facilitate response to events, typically with a sophisticated escalation path and method to document the response process. PagerDuty, VictorOps and xMatters are examples of incident management tools. PagerDuty establishes escalation policies, as well as creates automated workflows and alerts users of incidents based on preconfigured parameters.
ITSM service desk tools log data such as what the incident was, its cause and what steps were taken to solve the incident. ServiceNow and Zendesk are two major vendors in this space. ServiceNow Incident Management is a root cause analysis and auditing tool that logs and prioritizes IT incidents. ServiceNow can prioritize incident events through a self-service portal, email and incoming events. It logs incidents by the instance, classifies them by level of impact and urgency, escalates as required and performs analysis for future improvements.







